 微博
微博为什么大模型接下来要看中国?

作 者 | 张津京
现在互联网和科技界最火的名词就是大模型,尤其是知识大模型。
微软投资的OpenAI公司在去年年底推出的ChatGPT,经过几次迭代迅速在社会面火起来。人们开始惊讶这种AI模型对于语言的理解和输出,开始体会到AI技术推动到一定阶段对人类社会和发展的帮助作用。
伴随着4月份ChatGPT4.0的发布,相应的技术水平得到了进一步提升,知识大模型对于人类提出问题的反馈精确程度也进一步得到了证实。
于是很多创业者和互联网的从业者,都开始站在ChatGPT4带来的冲击面前感到振奋异常,认为自己可能摸到了未来互联网乃至人类社会技术进步的趋势。

就我所参加的几个讨论ChatGPT或者知识大模型的群来看,大家热情很高,都希望在这个风口上成功创业,形成新的互联网巨头。
当然在群内所有人都认为,微软所投资的这家公司以及ChatGPT的技术,依然还是要优于国内现在陆续发布的十几个大模型的水平。而且在他们看来,随着硬件投入的不断加大,ChatGPT的未来发展高度是要远超国内现在已经发布的各个大模型。
而这个似乎成为了很多创业者都认可的一个“真理”。
我的一位了解大模型的朋友,曾经跟我忧心忡忡地表示,随着美国对中国高科技的打压和芯片的禁售,像英伟达顶级A100的AI芯片,只能阉割传输效率之后,变成特供中国的A800才能出口并向中国销售。从这个角度上讲,在硬件投入方面中国的企业天然要弱于微软扶持的这家公司。

在他看来,现在已经推出大模型的中国,企业硬件基础就比OpenAI 要弱很多,更何况微软还为OpenAI 培养了一个庞大的调教团队,并经历了8个月的深度调教,才让ChatGPT有了现在的水平。在他看来,这不是国内企业几个月就能超越和追赶的。
所以他觉得中国和美国在知识大模型领域的竞争,不是接近了,而是距离在不断拉远。
真的是这样吗?
01
实话实说,算上金山刚刚正式发布的WPS AI,最近两个月从百度的文新一言开始,中国企业陆续发布的大模型已经超过了20个。
这似乎让很多人又看到了之前在元宇宙和团购平台领域出现过的中国特色:一拥而上与疯狂烧钱。

毕竟想搭建一个类似ChatGPT的大模型环境,就绕不开英伟达的特供芯片,哪怕是阉割版,英伟达也敢卖到一颗几万美元。
这意味着想要成功拿出一个还能看得过去,甚至能日常实现部分功能的知识大模型,其背后投入的硬件资源和软件开发能力,是一个天价。
从这个角度上说,凡是可以在发布大模型之后,就敢公开提供公众测试的平台,恰恰说明他们的投入还算到位,而那些用PPT发布模型后无法测试,哪怕开放测试申请却迟迟得不到通过的大模型,可能核心资源的投入上有着重大的问题。
也正因为现在出现了似乎过热的现象,才引发周鸿祎这样的行业大佬出来声明,希望大家能踏踏实实的做技术,最好要用两年的时间赶上ChatGPT3.5的水平。
这一点现在的情况我并不否认,而且这种市场的乱象,我认为还会持续一段时间,毕竟很多上市公司跟股价的需求相关,他们一定会炒作类似的概念。
但大浪淘沙,不能一杆子把所有的中国企业努力都抹杀。
现在中国企业真正要看大模型的能力,其实并不是看现在资源的投入,而是要看他们在之前这个领域有多少强大的积累。
比如最先发布国产大模型的百度。
百度李彦宏扭转企业发展的方向,将百度的未来押宝到AI上面,这已经经过了十几个年头。而近十年百度的财报显示,百度在研发上面的投入以及在收入上的占比是逐年提升。2013年还是40多亿元人民币的投入,到了2022年就已经超过了220亿元。
这其中绝大多数的研发经费投入到了自动驾驶和AI开发上。

实际上提到AI在中国的发展,百度是绝对绕不开的一个企业,因为现在很多AI的研发者和程序员使用最多的中文开发平台飞桨,就是百度开发并不断迭代使之成熟的。
而在大模型领域,其实百度与OpenAI 的进度差不多,都是在2019年前后搭建了自己的大模型。谁都不清楚的是,2019年百度的文心大模型就已经悄然出现,而且当时定义的就是一个语义理解和多模态生成的大模型。
正是在这个大模型的支持下,2021年百度百家号悄然上线了图文转视频的功能。到了2022年,经过两年的迭代,百度文心大模型已经在向所有的互联网用户提供图片生成的功能,这就是现在很火的文心一格。
从这个角度看,百度快速迭代推出通用大模型和聊天工具文心一言,实际上是有着自己的资源和技术积累。并不是说百度看到ChatGPT崛起之后,用一个月的时间迅速开发了一个程序套壳搜索引擎就向大家提供服务。
再比如之后发布大模型的阿里。

实际上他们接触大模型,甚至建立阿里自己的通义大模型,也是在2019年前后。而且跟百度不停的推出类似产品来测试模型的应用方向不同,阿里由于跟云业务的紧密结合,他们一上来就是用to B的思维在做这个产品。
2022年年中阿里就上线了可以帮助企业自己来调试封装私有大模型的工具,并且在阿里云已经独立成一个产品,这种能力实际上是早于OpenAI 发布ChatGPT的时间点。只不过当时阿里所提供的模型还是专一模型,针对的是细分市场和细分应用。
当然还有上个星期刚刚发布星火大模型的科大讯飞。
实际上如果说语义理解,全中国做的最好的应该就是科大讯飞,因为他们结合声音的输入,已经把自己的产品玩的明明白白。而背后十几年关于人工语音录入的理解和AI的转化,是科大讯飞对于语义理解大模型,或者说是知识大模型中语意理解部分最深刻的积累,这恐怕是OpenAI 对于中文都不具备的。
所以他们在看到ChatGPT的表现之后,就明白了自身积累的资源如何迅速的转化,而星火大模型打磨完善拿出来的情况,我们发现很多在于情感方面的表达是优于ChatGPT3.5甚至ChatGPT4的。
这就是优势。
02
我并不否认ChatGPT4目前为止依然是全球技术和应用反馈最领先的大模型。而国内几家大模型的发布方实际上或多或少都表示过,目前还处于追赶ChatGPT3.5的一个水平。
问题是,中国的大模型虽然只是刚刚起步,但我们有着别人不具备的优势。
这就是应用环境和商业能力。
这句话可能让很多创业者感到诧异。难道说不是美国的互联网商业模式更先进吗?
实际上在ChatGPT这件事情就能看出,微软现在有一些举棋不定的意味。而微软对于大模型商业变现方式的“难产”,背后实际上就是互联网商业模式,现在在美国“逐渐枯竭”的一种表现。
从OpenAI的角度来说,商业化是其现在工作的重中之重。而4月1号之后不再受理免费API申请和用户注册,现在要不断推出各种的plus收费版本,OpenAI已经将接口付费和使用付费的原则逐渐体现出来。
这是非常明确和简单的事情。

最新的消息显示4月底他们又拿到了一笔103亿美元的融资,加上今年早期微软给的100亿美元,在今年年内,OpenAI就快速融资了200亿美元左右的资金。
OpenAI从一家不求盈利的研发团体,转变成一家谨慎盈利的商务公司,创始投资人马斯克的退出是个分水岭。而之后微软就开始疯狂对这家公司进行投入,前后已经投入将近80亿美元。
从其融资的轨迹,大概能推算它烧钱的速度。
在之前实验室和后期调教的阶段,微软两年投了80亿美元,也就是说当时的资源堆砌是系统调教和硬件堆砌的结果。
在正式开放ChatGPT3.5之后不到三个星期,微软紧急追加了100亿美元的一个投入,这明显是OpenAI接受公开访问后硬件条件无法支撑,必须快速扩容的一个紧急融资。
然后在ChatGPT4上线后,不到一个月它又传出顺利融资103亿美元的消息,而结合ChatGPT4的接口排队非常大,并且每个月审核通过的数量有限,可以看出新一轮的硬件拓展是OpenAI最近忙于解决的重要问题。
目前来看这家公司现有的商业模式,并不具备能弥补上投入的能力。
因为根据OpenAI的规划,其主要的盈利方式就是plus版的付费,大概一个月20美元。当下OpenAI3.5的接口访问已经到了10亿人次的规模,按照一般互联网平台1%左右的付费用户转化率,那么就有1000万人愿意每个月支付这20美元的使用费。从这一点上看,OpenAI现有收费模式,一年的收入水平是24亿美元。
当然,一般来看这种平台类的公司还需要向B端拓展和向其他平台赋能。一般情况下大概都是许可费,还有就是使用费的模式。
根据微软之前披露的自身技术许可和使用费产品,互联网平台收费的价格来估算,平均一个互联网平台拿到微软承包技术的年使用费是100万美元,而在美国,微软这种服务的互联网企业也不过200余家。OpenAI我们认定其马上就能从微软原有客户中获得收益,这部分的收入一年差不多是在2亿美元左右。
因此,单靠这两种模式无法满足需求,OpenAI必须另找他法。
不得不说OpenAI有高人,其现在已经上线了在其聊天的过程中可以连接到其他应用的能力,这实际上未来就是流量分成的模式。

他想抢夺的实际上是谷歌之前业务中最重要的互联网广告模块。这个才是OpenAI,现在可以想象的,最终拓展营收最重要的入口。
因为谷歌差不多一年广告的收入在2,200亿到3,000亿美元之间,OpenAI如果能杀入这个市场,从其中切到15-20%就能满足自身投入和未来盈利的需要。
但真正的问题在于OpenAI可以预见的盈利模式,实际上是对美国互联网市场的存量再分配。并不是一个跨越式或者降维打击的情况出现,甚至新的商业模式也没有发生。

这对一个国家的互联网产业发展,其实并不利。
这意味着OpenAI的大模型技术非常好,但它真正引发的是美国互联网行业的内卷,而不是美国互联网商业模式的向外扩张。
03
我特别理解OpenAI乃至于微软急于把ChatGPT商业化的诉求。
实际上也纠正大家一个概念,大模型并不能像人类大脑一样,学会了什么东西就可以快速的反应出来,形成一个很短的信号连接。ChatGPT模型是一种自然语言处理(NLP)模型,使用多层变换器(Transformer)来预测下一个单词的概率分布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本。
换句话说,每次大模型对于人类提问的反馈,都是经过一个复杂运算的结果。
而对于ChatGPT的训练,实际上是一个非常费钱的过程。

这是中信证券做的一个统计表,现在看ChatGPT3.5每次训练成本就超过1,200万美元,更别提比他更高级的ChatGPT4。有专家预计ChatGPT4的训练一次会超过5,000万美元。
对于ChatGPT来说,并不是训练完成就解决问题,相应的硬件一次投入之后,每个月还要产生额外的使用费用和拓展费用。
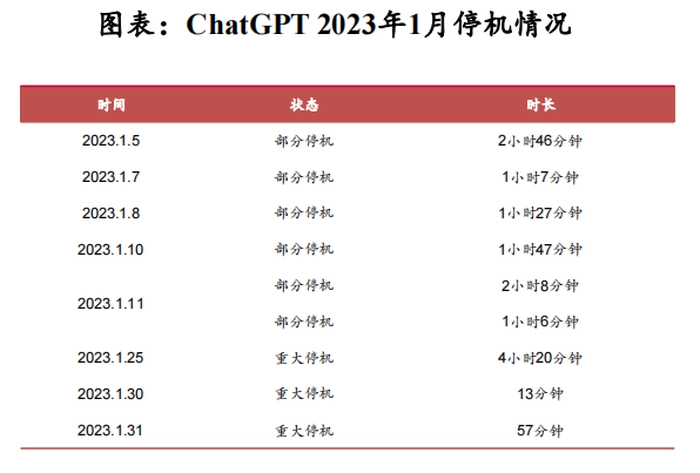
2023年1月ChatGPT访问量环比增长119.4%,用户访问量的激增导致ChatGPT发生了因云算力不足而宕机的情况。据OpenAI数据,1月ChatGPT重大停机(Major outage)时长为5小时30分钟,部分停机(Partial outage)16小时21分钟,运营算力不足已经开始影响ChatGPT的稳定性和响应速度。
ChatGPT 海量的参数与强大的智能交互能力,离不开算力的支撑。根据Similarweb 的数据,2023年1月份ChatGPT日活约1300万人,累计用户已超1亿人,创下了互联网最快破亿应用的记录。若 ChatGPT日活达至10亿人,每人平均1000字左右的问题,那么需要多大的算力资源支持?
中信证券对此做了评估,发现ChatGPT3.5如果应对10亿人次访问,每人深度使用,平均每日万字问题,那么需要投入英伟达最新A100服务器超过46万台。

毫不夸张地说,以英伟达现在“掉钱眼里”的特性,单块A100芯片卖出的价格已经是天价,而在这种天价基础上组建近46万多台的服务器,对于研发和运营团队的压力可想而知。
这也是为什么ChatGPT还远没达到真正理想状态,微软就已经迫不及待推出一系列依靠其发展的商业产品原因,这也是 OpenAI正在布局商业化,并且将其作为最重要工作的原因。
但这里边是有一些问题所在。
04
现在看微软对OpenAI相应技术的商业化就集成在必应新搜索和office365中的工具端。必应搜索对应的是谷歌的广告市场,office365中的工具是额外收费的一种产品。
同样OpenAI的商业化也集中在企业和用户单独付费使用,以及分割谷歌广告市场,这两个方向上。
某种程度上,大部分to C的这样商业模式,并没有给美国互联网市场带来一个增量,反而形成抢夺原有领军企业市场的一个局面。
大家都知道大模型接下来的破局肯定是在to B的商业模式上。AI只是提供了授权使用的方式,目前还并没有显现商业模式的核心,微软则是将其放到了自身云服务上,提供对于客户调教私密大模型的支持,但那些能力也仅是封装在一个小区域内进行,并不是真正的私有化。

再深度下去与行业相结合,目前看 OpenAI乃至于微软,并没有列入议事日程。
做过云服务的企业都知道,在云服务快速普及之后,真正能赚钱的市场一定是跟企业和行业深度融合的市场,SaaS、LaaS和PasS,是这样市场能力的深度体现。
某种程度上,如何利用大模型快速服务好企业,并帮助行业找到新的发展路径,进而产生增量的市场空间,才是未来大模型,可持续发展商业模式的根本。
这才是我说ChatGPT的未来在中国的真正原因。
因为中国的数字化进程是有着美国乃至其他国家完全不一样的过程和发展模式。我们的企业家无论大小,都对数字化抱有着强大的热情,他们认为数字化是企业发展必须的能力。
这其实就开启了一个无比庞大的to B端数字化应用市场。
同样,这也是为什么国内企业敢疯狂投资大模型,并且能有将近20多家拿出成果的一个重要原因,因为to B端的市场无限大,而且各个细分的行业需要符合这个行业实质的大模型来服务。
05
我不是说OpenAI的技术不好,我也不是说中国企业的技术已经赶上了美国最先进的水平。但在企业端应用的水平上,通用大模型不是最合适的,反而训练量放到一定的范围,训练数据也放到一定的范围的行业模型,可能才是最合适的。
这其实就给了中国企业弯道超车的机会。

比如在这个热潮中,华为就没有发布通用大模型。反而他们针对几个不同的细分行业,单独做了自己的行业模型,并且已经投入服务客户的过程,还取得了非常不错的效果。
这其实体现出的是中美在互联网底层商业模式上已经日行渐远的趋势。
从2018年腾讯提出“扎根消费互联网、拥抱产业互联网”的战略开始,与实体经济融合,就成为中国互联网企业找寻自身发展通路的重要手段和首选途径。
这其实就是中国互联网企业在大模型竞争中的底气。
因为对于一家特定客户的需求,不是一个通用大模型就可以满足的,必须是针对客户的需求定制化之后,又对其进行深度优化的结果。
比如阿里云,为了一个地方金融机构需求,可以组织100多位工程师驻场半年,在解决客户所有的需求之后“一揽子交钥匙”。
这种深度到市场、下沉到客户的能力,才是未来大模型技术进军B端客户需要比拼的。而在这一点上,美国的互联网企业这几年的课缺的比较多。
同样大模型现在所有人都看好的一个应用,是直接作用到制造业生产上。美国的大学已经推出,可以利用大模型指挥工业机器人的应用。
然而那套实验室中的东西真正放到一线制造业,已经变成一个笑话。
毫不夸张,为这件事我曾经还特意@了几位云服务领域一直在做一线制造业客户的技术专家。他们看后纷纷表示,这只是一个实验室的测试,把相应的技术拿到一线制造业的数字化过程中,会产生很多无法解决的问题。
中国每年消化了全球生产制造机器人的近七成市场,我们是全球制造业机器人使用最多的国家,没有之一。而制造业机器人真正的难题是针对于用户自身生产的工序要进行细微的调整,这些调整都必须到用户的身边,根据用户的需求来做。
这些工业用户用机器人的绝大多数都涉及到核心工序,而这些核心工序的过程和生产的资料是绝对不能外泄的,这意味着哪怕部署大模型,也必须是在用户线下本体的私有大模型。
同样,每家用户在各个不同的关键节点,可能要使用不同生产企业提供的工业机器人,相应的接口,现在都是靠三方平台的能力来做协调。换句话说国际制造业机器人,小到接口,大到数据传输,虽然归拢到几个核心的标准使用上,但每家基本上都是不同的一套体系,都需要三方公司帮助生产企业进行软件上的调整和适配。
这些不是一个通用大模型就可以解决的事情,必须深入到一线去。
所以这就成为中国相应服务企业,尤其是推出大模型的平台企业接下来弯道超车的机会。
我们欣喜的看到,不论是百度,阿里还是华为、科大讯飞,几乎全部推出大模型的中国企业,都已经将行业模型作为其最重要的产品和应用领域,并且针对自身的优势进行了深度的开发和研讨。
这才是真正的根本,也才是未来中国知识大模型发展的机遇,更甚点说,或许这才是知识大模型的真正用处。
数实融合才是经济发展的真正基石,这句话,放到当下大模型异常火爆的现实中,依然具备指导意义。
与所有想从大模型发展浪潮获得创业与发展机会的企业家和创业者们共勉。













